









30/06/2023
Formation à Hyperbase
 Dans le cadre du projet ANR Tractive, l’équipe BCL (Bases, corpus, langage) de l’université de Nice m'a accueillie, le 22 et 23 juin 2023, ensemble avec Léa Andolfi (doctorante du projet Tractive) et Marceau Hernandez (assistant de recherche CERES) (voir photo) pour un atelier de formation à Hyperbase, logiciel universitaire téléchargeable d'exploration documentaire et statistique des textes, dont la version actuelle est développée par Laurent Vanni.
Dans le cadre du projet ANR Tractive, l’équipe BCL (Bases, corpus, langage) de l’université de Nice m'a accueillie, le 22 et 23 juin 2023, ensemble avec Léa Andolfi (doctorante du projet Tractive) et Marceau Hernandez (assistant de recherche CERES) (voir photo) pour un atelier de formation à Hyperbase, logiciel universitaire téléchargeable d'exploration documentaire et statistique des textes, dont la version actuelle est développée par Laurent Vanni.
Publié dans 7. Perfectionnement technique, 9. Corpus & co
30/04/2021
Formation à EXMARaLDA
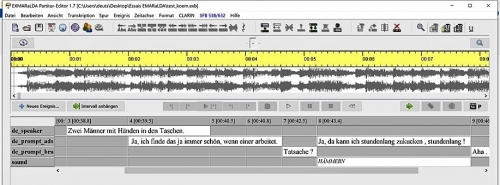 Dans le cadre de notre projet TADS (Translation of Audio Description Scripts), nous avons le plaisir de nous faire former à l'outil EXMARaLDA par son concepteur Thomas Schmidt, actuellement directeur de la section Mündliche Korpora - Pragmatik (Corpus oraux - pragmatique) au Leibniz-Institut für Deutsche Sprache (IDS) à Mannheim en Allemagne. Cet outil interopérable permet de transcrire, d'annoter, gérer et analyser des données orales. Nous comptons nous en servir pour afficher les différentes versions de scripts d'audiodescription, c'est-à-dire l'original et les traductions disponibles et celles créées par nous.
Dans le cadre de notre projet TADS (Translation of Audio Description Scripts), nous avons le plaisir de nous faire former à l'outil EXMARaLDA par son concepteur Thomas Schmidt, actuellement directeur de la section Mündliche Korpora - Pragmatik (Corpus oraux - pragmatique) au Leibniz-Institut für Deutsche Sprache (IDS) à Mannheim en Allemagne. Cet outil interopérable permet de transcrire, d'annoter, gérer et analyser des données orales. Nous comptons nous en servir pour afficher les différentes versions de scripts d'audiodescription, c'est-à-dire l'original et les traductions disponibles et celles créées par nous.
La formation aura lieu en juin 2021, à notre grand regret à distance, mais une rencontre en présentiel est prévue en novembre 2021. L'équipe de l'Institut d'études de traduction et de communication spécialisée de l'université de Hildesheim (Allemagne) et Thomas Schmidt se déplaceront alors à mon lieu de travail.
J'ai fait la connaissance de Thomas Schmidt et d'EXMARaLDA lors de la formation de dix jours CLARA Summer School à Nijmegen (Pays-bas) en juin 2010. Par la suite, j'ai utilisé EXMARaLDA pour transcrire des entretiens post-recherche en langue française.
06/08/2013
Perfectionnement technique
25 novembre 2021 – Formation à l'utilisation d'EXMARaLDA pour l'exploration et l'annotation de données d'audiodescription multimodales, Inspé de Paris. Formateur : Thomas Schmidt, Université de Bâle (Suisse).
30 septembre 2021 – Atelier proposé lors du Colloque "Vers une robotique du traduire ?" à Strasbourg : Le système de traduction automatique neuronale MateCat (outil de traduction assistée par ordinateur basé sur le Web). Formateur : Loïc Barrault (University of Sheffield, Le Mans Université).
19 janvier 2021 – Online workshop: Visual discovery tools in TRIPLE (Transforming Research through Innovative Practices for Linked interdisciplinary Exploration). Huma-Num.
24 juin 2020 – Webinar: Doing corpus linguistics with #LancsBox (V5). Workshop leader: Vaclav Brezina.
18 juillet 2018 - Using corpora to teach sociolinguistics: A practical workshop. Introduction into #LancsBox. Workshop leaders: Vaclav Brezina, Dana Gablasova, and Irene Marín Cervantes. Pre-conference workshop, TaLC13, Cambridge (Angleterre).
19-20 juin 2017 et 11 septembre 2017 : "Initiation à R". Formateur : Dylan Glynn (Université Paris 8 Vincennes – Saint-Denis). Formation organisée par le laboratoire CeLiSo (Université Paris-Sorbonne).
20 juillet 2016 - Introduction to statistics for linguistics with R. Pre-conference workshop TaLC12.
19-24 juin 2016 - École thématique CNRS MISAT - Méthodes informatiques et statistiques en analyse des textes (Besançon).
22 et 29 janvier 2016 et 25 mars 2016 - Ateliers AntConc et TXM, organisés par le laboratoire CeLiSo (Centre de linguistique en Sorbonne). Formateurs : Daniel Henkel, Pierre Labrosse et Kim Oger.
26-29 mai 2015 - Initiation à l’édition électronique et la pratique de l’encodage XML/TEI (formateurs : Lou Burnard, Emmanuel Château). Stage organisé par l'École nationale des chartes.
2-3 décembre 2014 - Ateliers TXM : "Initiation à TXM" (Bénédicte Pincemin) et "Préparation de corpus et import dans TXM" (Serge Heiden), ENS Lyon.
Mai - juin 2014 - Mooc "Monter un Mooc de A à Z" (plateforme FUN).
2012/2013 - Séminaire doctoral "Informatique pour la recherche. Approches textométriques, ergonomies numériques", proposé par Jean-Marc Leblanc, UPEC (Université Paris-Est Créteil Val de Marne).
9-10 juin 2011 - Formation LODEL utilisateurs (logiciel d'édition électronique), organisée par Cléo (Centre pour l'édition électronique ouverte), Paris.
22 février 2011 - Tutorium der Sektion Computerlinguistik. Korpuslinguistik mit Online-Ressourcen — eine interaktive Einführung für Linguisten [Atelier "Linguistique de corpus basée sur des ressources en ligne - une introduction interactive pour linguistes"]. 33. Jahrestagung der DGfS (Deutsche Gesellschaft für Sprachwissenschaft), Georg-August-Universität Göttingen (Allemagne).
5-16 juillet 2010 - Formation CLARA Summer School on Advanced Resource Creation, Archiving and Usage à Nijmegen (Hollande).
12 mars 2010 - Atelier d'initiation à COSMAS II (Corpus Search, Management and Analysis System) proposé par l'IDS (Institut für Deutsche Sprache) à Mannheim (Allemagne).
1er juillet 2006 - Atelier d'initiation à Sketch Engine, proposé par Adam Kilgarriff lors de la 7ème Conférence TaLC (Teaching and Language Corpora) à Paris 7.
Publié dans 7. Perfectionnement technique, 9. Corpus & co
06/12/2010
CLARA Summer School 2010

En juillet 2010, j'ai eu l'occasion de participer à la CLARA Summer School, organisée par le MPI (Max-Planck-Institut) à Nijmegen en Hollande. Dans une ambiance hautement internationale, j'ai eu la joie d'entendre des exposés, présentés par des spécialistes du son, de la vidéo et des banques de données. J'ai pu essayer de nombreux outils, comme ELAN, Praat, Folker, EXMARaLDA, R, etc. J'ai vu que les corpus multimodaux offrent de belles possibilités pour l'enseignement-apprentissage des langues étrangères. Voici un rapport concernant cet évènement, publié sur le site du MPI Nijmegen.
Publié dans 7. Perfectionnement technique, 8. Colloques & co., 9. Corpus & co